Introduction
Current State of Network Automation
If you ever visited network related conferences in the last 10 years and attended (and listened to) the talks, you were bound to hear network automation success stories. Usually they show how people started out using network automation tools, be it Ansible,
Saltstack, or self-written tools for example based on Python and ncclient, or vendor supplied libraries like JunOS PyEZ. This is what we consider as network automation for the past decade: write templates, fill templates with device-dependent variables, push
result to the device.

It helped us a lot in managing our devices. We gained reliable, solid configuration on all devices, same defaults everywhere, identical configuration for base configuration, services and everything in between. But looking at the current state of the networking industry this is not really automation anymore. I would like to coin the phrase “templating” for this.

In order for this to work, the network engineer needs to write the configuration templates, and in the process define the necessary variables needed.
Templating: writing configuration templates, filling them with variables and pushing configuration to network devices.
Over the years the ecosystem for this templating has been growing and became mature enough to use on networks of all scales. We have ansible, Saltstack, various Python modules for writing our own code to build templates and push on devices. We have many talks, blog posts, videos as documentation how to use those tools. We extended the tools to fit all necessary needs, thanks to open source implementations this is available to everyone.
Theory of Network Automation: Intent-based Networking
At the same time, starting from a different direction, the theory of network automation was advancing. We got introduced to terms like intent-based networking, work out the theory around it and describe a (theoretical) world in which we do not need to write specific configuration for a device vendor anymore, but can write an intent:
“I want a P2P service from device foo, port P1, VLAN 1200 to device bar, port P10, VLAN 912. And make it orange please.”
Then some magical software would take this and translate it into the necessary network configuration.
In some instances, this implementation was also available, but mostly from network vendors and for obvious reasons for their devices, not across multiple vendors an devices. Hence the add-on “theoretical”: while the concept is sound, there is currently no easy way how to make the concept of intent-based networking happen by default in a normal service provider network. We as engineers need to bootstrap everything, and then we can reap the results.
Summary
In short: we as an industry are now in a very good place to write templates with variables, merge those templates with specific variable configuration for a device and push this configuration to any number of devices. No one needs to configure a new device from scratch anymore if they do not wish so.
However, with this knowledge come new questions: where are those devices we should configure the intent on? Which NOS are they running? What variables should we push on? Clearly the user should not supply a full intent with every configuration (think: vrf-target, loopback addresses, etc). There are missing part.
Documentation Systems
Enter: DCIM (Data Center Infrastructure Management)/documentation systems like Netbox, Nautobot or a wide variety of commercial systems.
Documentation systems are great. One of the reasons they were introduced: To create a single Source of Truth[tm].
It was considered a general consensus amongst network people that in the above described templating workflow we were lacking
some way to properly store the variables to fill the templates. Documentation Systems fill this void, and by guided us during
the input of the data.
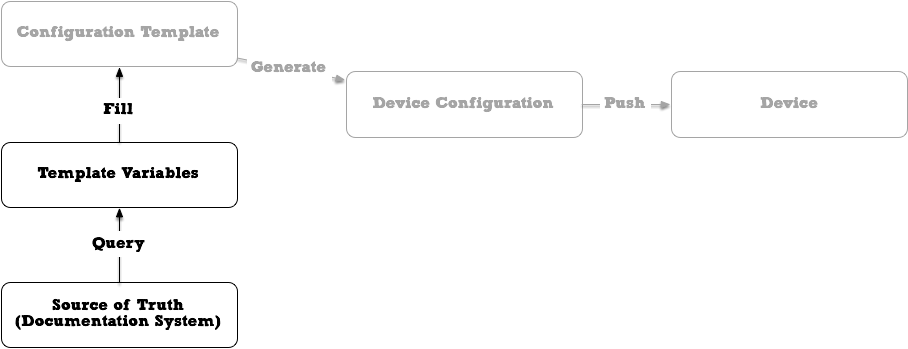
The greyed out parts we nailed already. But now we can query our Source of Truth where we document sites, racks, devices. We can document physical parameters:
- Device D1 is in rack R1, rack unit 12, in site S1
- It has transceivers in ports P1, P2, P4, P5 and P10
- It is connected on those ports to other devices and ports
However this is the easy stuff: it relates to the physical world and there is a general consensus how this needs to be modelled, since we have a physical equivalent.
Now we want to document logical parameters. Again, there are easy ones: we want IP addresses on Subinterfaces, we want VLAN IDs with global or local scope. There is in general consensus between DCIM developers and network operators about how to document
them.
But what about services? One operator has a Ethernet-based Metro Ethernet, another one is using LDP-based MPLS with Layer 2 Circuits, another one EVPN with VPXLAN underlay, and don’t forget the weirdos with SR-MPLS or SRv6 underlay or RSVP-based MPLS.
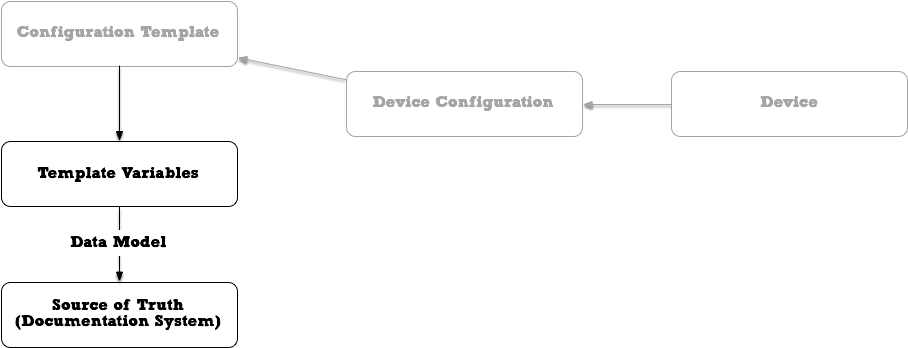
You want to document those in your documentation system? Then you need to sit down and figure out which parameters you need
in your document system for this. You need to study your documentation system, probably enhance it with custom fields or
re-use existing fields for your own purposes.
Or in short: you need to develop a data model for your specific purpose and
documentation system, document this data model, teach your colleagues how to use and obey to it, maybe write tooling around
it.
All this work is highly individual for each network and company, so current documentation systems really cannot cover this in their default setup. Best case scenario is: your documentation system is flexible enough so you can easily define and enforce your data model with it.
Realistic scenario: it is not. Given the variations in networks, services, devices which exist in the real world we cannot
expect that one data model or one documentation system can cover everything. We will always need to adapt existing systems to
our needs. Unfortunately currently this means using free-text fields, tags or other available existing fields in our software
to store this information.
Adaptation is always necessary. But we need a proper way of documentation for those adaptions, and a way how to do this work only once and not in multiple places at once.
Summary
So we are going away from the helpful guided approach of entering data in a documentation system, and at least in some areas going towards our own understanding of the data in our documentation system: we are basically treating our DCIM as a database, which gives us help in some areas (think: physical link between devices).
And restrictions we need to work around in other areas, for example if our documentation system does not have the necessary fields to enter the information we need.
Developing a data model
So what will a person (or a team of persons) do when they want to fully document their services in their documentation system? They sit down, they look at the system and what options it provides, look at their configuration templates which parameters they need to store, and build their own data model. They document this data model, write automation around it and hope that everyone using it will obey to the documentation. At the end they are rewarded with a full automation of their network, where operators need to fill the necessary fields in a documentation system with parameters, and services get configured without human interaction. Yay! This is what they wanted and for this specific team of people in this company this is a great success.
There is an alternative to this: if your automation level is high enough, you can also use a real database instead of a documentation system, thus modelling and writing everything from scratch. You gain a 100% suitable environment for you network, however you are likely going to repeat some mistakes which have already been discoevered and solved by developers of documentation systems.
Problems with this approach
Taking a step back and looking at the bigger picture however, there are some problems:
While a team at company A is doing this, many more people and teams at many other companies are doing the same thing.
Or maybe even: Engineer E1 who implemented this at company A is moving to another company B, where they haven’t progressed as far as his previous company, so they are doing the same thing there: figure out the DCIMs possibilities, figure out the required services and parameters, write a data model, document, write automation.
And the biggest problem of them all: The data model is linked to the variables which are needed in the configuration
template, which again are based on the devices you are automating, and in the other direction the data model influences where
and how you save those variables in your documentation systems.
Summary
If you want to change a confguration template, you might introduce new variables. So you need to adapt the data model, the documentation system and your documentation around that.
You might be developing and adapting data models and code for your foreseeable future in this job.
This reminds me a lot of the situation we have been in before templating tools existed, when configuring a new device is a manual chore for a network engineer. Luckily those times are over, but not so much for the data model part.
I think we are at a point in our industry where the next big step needs to happen, so we can progress further.
Something should to happen
I think we are ready by now to take a next big step. But what is the next big step exactly?
I don’t know. Speaking for myself, I can say: there is a nagging feeling we are at a point where we have enough knowledge to discuss amongst ourselves and come up with solutions which can make our lives easier in the upcoming decade of networking.
The steps to there definitely have something to do with data models, documentation systems, templating.
- How those systems interact with each other?
- Which information is needed in which step?
- How can we define this information in an efficient way
- Define it in one place.
- Let other places derive this information from the initial definition.
- Do we need to introduce a new “thing” which is helping us in those things?
We need to go deeper.
Writing from an algorithmic point of view: I want to go down one iteration step, adding more automation and algorithms to places which so far were done by humans. Increase automation, so we can concentrate on more fun things, and I don’t need to spend the next 10 years (re-)designing data models and re-inventing the wheel again and again.
Goal
Since we are missing some words in describing what we want, it is even harder to say what the ideal outcome would be. But here are some high level points I want to achieve:
- Define a a data model..
- .. which can be used to fill templates of all kinds
- .. where we describe what values needs to be saved in which field
- .. which works together with our existing documentation systems
- .. and existing templating solutions
- .. and does some magic so we don’t need to develop everything from scratch over and over again
The data model could be used the same way as configuration templates currently. It is comprised of atomic elements, which can are fleixble enough to be re-used in many places (think: ansible roles). The data model can be used to bootstrap a database as well as a DCIM as storage.
And of course we have a lot of open questions:
- How would a data model template/language look like?
- What needs to be covered by it?
- How would we get from a data model template to an actual database layout or DCIM layout?
What should we do about it?
Additional complexity comes from the fact that this is not solely a network engineering topic anymore, in contrast to templating which you could still cover with network engineers. We need specialists from various areas: software architects, data architects, network architects, developers working together.
The complexity, if we want to solve the problem immediately, is very high and the scope is way larger than anything we’ve seen so far in our industry. But maybe we can start with something smaller:
- Talk amongst ourselves about the missing vocabulary.
- Write checklists of what we are doing when creating data models for documentation system
- Compare those checklists and see if they have something in common
And this is the my main point: we should start a conversation about those topics. We should try to find common ground, maybe implement a few systems which are going into the direction we are envisioning.
Then learning from those, throw it away, build newer and better systems. Do the same thing we did iwth templating software +10 years ago:
Start with something simple, build on that, bring people together to find the language we are lacking and then solutions will follow. So in 10 years we can look back and say
Oh cool, now I can describe a data model and fully automate a network the same way I could template it previously, in a lot less time than before.
Wouldn’t that be nice?